隨著信息技術的發展,數據庫存儲與索引技術作為數據處理和存儲服務的核心,經歷了從簡單到復雜、從單一到多樣的演變。本文重點探討存儲模型與索引結構的演進歷程,并分析其對現代數據處理與存儲服務的影響。
一、存儲模型的演變
存儲模型定義了數據在數據庫中的組織方式,其演變主要經歷了以下階段:
- 文件系統存儲模型:早期系統采用簡單的文件結構存儲數據,如順序文件或索引文件。這種方式缺乏統一的數據管理機制,導致數據冗余和一致性問題頻發。
- 層次模型與網狀模型:20世紀60年代,層次模型(如IMS)和網狀模型(如CODASYL)出現,通過樹形或圖形結構組織數據,支持復雜關系。它們結構僵化,難以適應動態需求。
- 關系模型:1970年,埃德加·科德提出關系模型,以表格形式存儲數據,強調數據的邏輯獨立性和完整性。關系數據庫(如Oracle、MySQL)成為主流,支持SQL查詢,極大提升了數據管理的靈活性和效率。
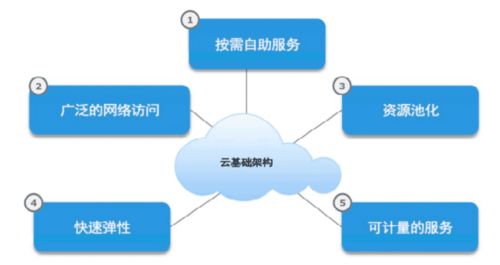
- NoSQL與NewSQL模型:隨著互聯網和大數據興起,非關系型存儲模型(如鍵值存儲、文檔存儲、列族存儲)應運而生,解決了海量數據和高并發場景下的擴展性問題。同時,NewSQL模型(如Google Spanner)結合了關系模型的ACID特性和NoSQL的可擴展性,推動了分布式存儲的發展。
二、索引結構的演變
索引是提升數據檢索效率的關鍵技術,其結構演進如下:
- 簡單索引:早期使用線性索引或哈希索引,適用于小規模數據,但查詢效率隨數據量增長而下降。
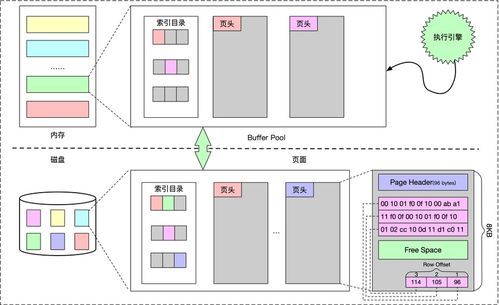
- B樹與B+樹:B樹及其變體B+樹成為關系數據庫的標準索引結構,支持高效的范圍查詢和順序訪問。B+樹的葉子節點鏈表結構特別適合磁盤存儲,減少了I/O操作。
- 位圖索引:針對低基數字段(如性別、狀態),位圖索引通過位向量表示數據,壓縮存儲并加速多條件查詢,廣泛應用于數據倉庫。
- 全文索引與空間索引:隨著非結構化數據(如文本、地理信息)的普及,倒排索引(用于全文搜索)和R樹(用于空間數據)等結構被開發,支持復雜查詢模式。
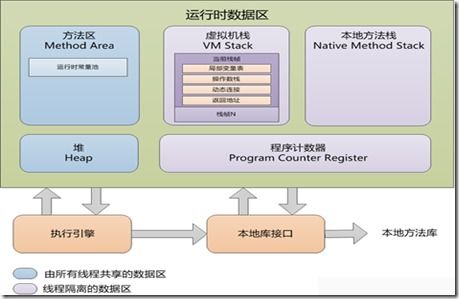
- 內存索引與自適應索引:現代系統引入內存索引(如T樹)以利用高速內存,同時自適應索引(如數據庫 cracking)根據查詢負載動態調整結構,提升實時性能。
三、在數據處理與存儲服務中的應用
存儲模型與索引技術的演進直接推動了數據處理與存儲服務的優化:
- 云數據庫服務:基于分布式存儲模型(如分片技術)和智能索引,云服務商(如AWS RDS、Google Bigtable)提供高可用、可擴展的數據處理能力,支持企業級應用。
- 實時分析:列式存儲模型(如Apache Cassandra)結合位圖索引,加速大數據分析,滿足實時決策需求。
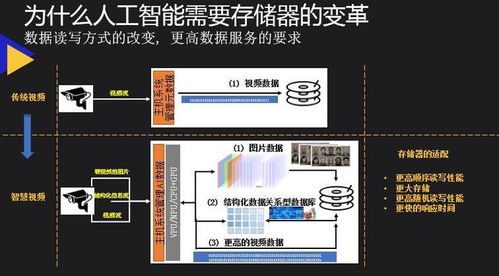
- AI與機器學習:新型索引結構(如近似最近鄰索引)助力向量數據庫,高效處理相似性搜索,應用于推薦系統和圖像識別。
結論
數據庫存儲模型與索引結構的演變,從文件系統到智能分布式系統,體現了技術對數據處理需求的持續適應。未來,隨著量子計算和邊緣計算的發展,存儲與索引技術將進一步融合AI,實現更高效、自適應的數據服務,為數字化社會提供堅實支撐。